阿里云发布新计算实例一项黑科技让Redis性能翻倍AI提升30%
随着人工智能、大数据应用的进一步普及和元宇宙的兴起,人们对算力的需求正成指数级增长。这种需求不仅体现在更强大的性能,还体现在更低时延、更快速地得到运算结果。
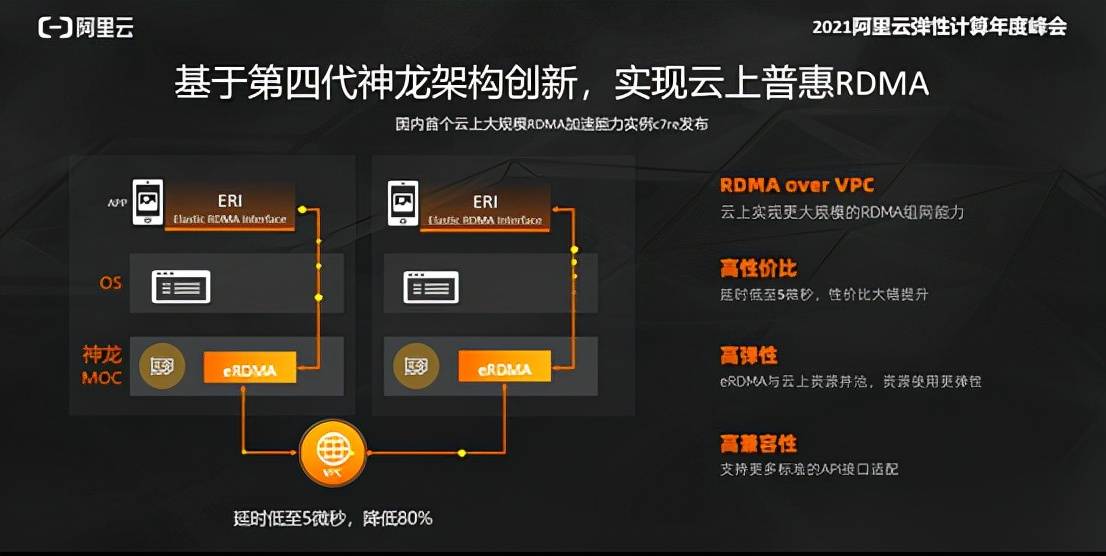
对算力的追求正是IT产业慢慢的提升的源动力之一。在日前举行的2021阿里云弹性计算年度峰会上,阿里云一口气发布了多款基于自研神龙架构的弹性计算新品,包括RDMA增强型实例、800G GPU超算实例、FPGA计算型实例、GPU图形计算型实例等,不仅在性能方面大幅度的提高,同时增加了多种服务形态,为公司可以提供了更丰富也更具性价比优势的产品服务。其中,RDMA增强型实例c7re、800G GPU超算实例更是让人眼前一亮,c7re是基于第四代神龙架构的首款产品,将Redis混合读写性能提升130%,将AI深度学习场景性能提升30%。同样搭载RDMA高性能网络的还有800G GPU超算实例,将模型训练效率最大提升9倍。
RDMA是Remote Direct Memory Access的缩写,直译是远程直接数据存取。RDMA本质上是一种内存读写技术,它将数据直接从一台计算机的内存传输到另一台计算机,无需双方操作系统和CPU的参与。RDMA的好处是能节省宝贵的CPU资源,还能实现高吞吐、低延迟的网络通信,很适合在大规模并行计算机集群中使用,此前主要使用在于高性能计算领域。
近年来,随着大数据分析和AI应用兴起以及一些浪涌型IO高并发、低时延应用出现,网络传输瓶颈问题开始凸显,人们希望能够通过RDMA的高速通信能力解决两个问题,即海量数据的传输和时延。
第一个需求以大数据分析和AI训练最为典型。这两类应用有一个共同点就是数据量大,数据交互频繁。如今数据集群规模慢慢的变大,数据分析规模动则达到PB级,AI训练模型参数达到万亿级。比如,阿里巴巴达摩院推出的多模态大模型 M6 参数达到 10 万亿。同时,大数据分析和挖掘的时间周期慢慢的变长,时效性越来越差,严重影响了业务的效率。
第二类是时间敏感性业务需求。比如,互联网场景下数据库业务通常承载高并发的业务需求,尤其是内存型数据库(如Redis)对时延有极高的敏感度。另外,还有工业仿真、无人驾驶等也是对延时极度敏感的业务场景,过大的延迟极度影响应用的效果。
传统RDMA虽能满足数据传输的性能需求,但是业务的弹性上往往无法很好的应对,而且应用场景和规模受限。传统RDMA的不足大多数表现在两个方面:首先是成本,目前实现RDMA的实现方式主要有IB网络、RoCE网络,都需要专用的网卡和交换机(这些设备通常价格昂贵),同时需要配备专人运维,而且需要对应用做改造。其次,传统RDMA难以大规模组网,一旦规模上来,非常依赖于交换机的流控能力,否则网络通信质量会迅速下降,丢包严重,系统很快面临崩溃。

“RDMA的典型应用场景是高性能计算,这种规模都不太大,比如几百台、上千台服务器的规模情况下,RDMA确实提供非常极致的延时体验,延迟能够达到1~2微秒左右。但是,由于不能在上万台、数万台规模集群用RDMA进行网络通信,因此无法直接用在云环境中。”阿里云弹性计算产品线负责人张献涛在接受媒体采访时表示。
张献涛说,规模化对云最重要。毕竟,云数据中心都是几万台服务器起步。在上万台服务器规模的场景下,怎么样才能解决RDMA的规模化和成本等不足,以满足大数据、AI以及高性能计算的上云需求,成为阿里云研发弹性RDMA网络的主攻方向。这其中技术挑战很大,阿里云围绕RDMA进行了多年研发,直到2021年10月份在云栖大会上阿里云推出第四代神龙架构,并宣布首次搭载弹性RDMA网络,阿里云的弹性RDMA才正式对外公开。
实际上,这些年来为满足各种不同应用对数据高速传输的需求,人们一直在一直在改进RDMA,先后有了IB、RoCE、iWARP等各种协议。阿里云研发的弹性RDMA本质上与它们一样,只是阿里云没有给它一个新名字,简单称之为弹性RDMA(eRDMA)。
张献涛解释说:“我们内部也给这个RDMA协议取名了,但对外我们仍旧是用通用名字来描述它,主要是希望让客户能够从产品的视角去看待RDMA,这里‘e’强调的是在云上的弹性。”

张献涛介绍,阿里云对传统RDMA的改进本质上是在几个因素,包括延迟、规模化、可靠性等之间做平衡。比如,传统RDMA和RoCE、IB一样,延迟很小但可靠性不高,而且难以大规模部署。另外,传统高性能计算中心里使用IB网络架构,从应用模型到下面的通信模型都比较固定。但是,在公有云平台上应用复杂多样,可能是AI也有一定的可能是大数据、HPC,还有很大的可能是微服务,要让改进后的RDMA能适用更多应用类型,更是要做好可靠性、规模化和延迟等众多因素之间的平衡。
数据表明,阿里云的平衡做得很优秀。张献涛分享了几个数据:传统的RDMA延时能做到1~2微秒,阿里云弹性RDMA延时低至5微秒,但传统RDMA规模只能做到1000台左右,而阿里云弹性RDMA能做到10万台以上,提升了100倍。另外,传统RDMA在可靠性方面依赖于交换机的优先级流控,而阿里云部署于普通交换机上就能确保可靠传输。另外,阿里云面对的是多租户应用,为此提供了RDMA over VPC的能力来进行多租户的隔离。
阿里云能做到这一切的秘密武器就是阿里云的神龙架构,搭载大规模弹性RDMA加速网络第四代神龙架构,将网络延迟整体降低80%以上,第一次将云计算带进5微秒时延时代。
阿里云通过神龙架构的软硬件结合和协同设计的思路,实现了自己的RDMA协议。而且在实现底层协议的时候,保持了上层的应用编程接口,比如兼容Verbs的编程接口,这样传统的高性能应用直接就可以用,而大数据或者AI类应用也只需要做简单的接口适配,就能够得到RDMA网络带来的高性能通信能力。另外,还有很重要的一点是,阿里云的弹性RDMA大幅度降低了应用门槛,无需专用设备和专用网络,用阿里云神龙服务器和VPC网络实现了RDMA技术,而且足够有“弹性”,想用就能用,随开随用,无需花长时间部署,不用专门做优化。
实际上,无独有偶,AWS也从其视角出发研发了类似的技术,这就是EFA。张献涛说,与AWS的EFA相比,“大家在场景需求思考路径一样,但是在具体的实现,在软硬件接口的协同设计方面,神龙架构有自己的优势,比如传输可靠性、延迟等方面。”
神龙架构是阿里云自研的一个软硬一体的虚拟化架构,张献涛正是神龙架构的提出者与发明者。第一代神龙架构于2017年正式对外发布,到今年10月份的云栖大会上阿里云发布最新一代神龙架构,已经演进到了第四代。神龙架构通过把虚拟化转移到专用硬件中进行加速,将物理机的高性能与虚拟机的灵活性融为一体,虚拟化损耗几乎为零,性能比传统物理机更强劲,还可随时扩容,极大降低了客户的成本。
本质上神龙架构和当下热门的DPU要做的事情是一样的,都是未解决虚拟化后的管理损耗问题,而把CPU的一些非必要的管理工作卸载到专用芯片(如DPU)中,但阿里云多年以前就提出了整个思路并在2017年有了第一代研究成果,这也正是阿里云的领先之处。实际上,不只是阿里云,AWS也在差不多的时间推出了自己的DPU,这就是AWS的Nitro系统,目前Nitro系统也同样演进到第四代。

“我们两家都是在云计算做到一定规模的时候遇到了瓶颈,这就是性能很难提升上去,成本降不下来,服务的品质也是提升不上去。在共同的问题的驱动下,大家不约而同地选择了研发DPU。”张献涛说。
研发DPU的深层原因主要在于,目前的IT架构中是以CPU为中心,CPU不只是要进行各种复杂计算还要负责管理和调度各种资源,比如虚拟机的调度和管理、网络通信的加解密和数据包的封装以及各种安全策略的执行等。有研究多个方面数据显示,上述这部分工作可能耗用CPU 30%的算力。把这部分工作卸载到效率更加高的专用芯片上,不但可以提高计算效率,还能够更好的降低总体拥有成本,对那些拥有几十万到几百万台服务器规模数据中心的云服务商而言,无疑非常有意义。更重要的是,面对超大规模数据处理的需求,CPU的算力已达到瓶颈,为CPU减负势在必行。
其实不仅是云服务商很关注DPU,在DPU有望成为继CPU、GPU之外数据中心第三大芯片的憧憬下,更多的厂商投入DPU的研发中,其中不乏像英伟达、英特尔这样的行业巨头。不过,在张献涛看来,真正能够把DPU做出来,还可以大规模应用的,一定是云厂商。
“不管是架构设计还是功能特性,云厂商一定会走在传统设备厂商的前面。因为云厂商有真实业务场景体验,会从业务视角出发,而传统厂商因为缺乏业务视角,是很难做出一个通用的DPU,它们更多的是参照云厂商定义的标准然后再研发自己的DPU。”张献涛说。
作为新一代虚拟化技术的代表,第四代神龙架构代表了目前DPU最先进的技术水平,其在IO加速、芯片级安全、云原生弹性和高速网络四大领域做了非常多的优化,因而为数据库、AI、大数据等通用场景带来性能的飞跃,弹性RDMA就是众多新增的特性之一。
张献涛表示,在激烈的市场之间的竞争环境中,掌握关键核心技术逐渐重要。今天已经全方面进入云时代,算力越来越集中在一些大型云服务商,如果说像DPU这样的技术不自己掌控。如果出现故障,需要修复其中的Bug,后者解决一个安全问题,可能会面临灾难性的后果。
实际上,不止是DPU,在服务器、网络、存储乃至整个基础架构的关键核心技术上,阿里云都在发力。以芯片为例,在今年10月的云栖大会上,阿里就发布了自研的Arm芯片倚天710,搭载这款Arm芯片的实例不久会上线。除了通用Arm芯片,阿里还在专用芯片上发力,推出了含光800、玄铁910等。正因为多年坚持关键技术的研发,在Garnter刚发布的IaaS+PaaS解决方案能力评估报告中,阿里云IaaS基础设施能力成绩优异,在计算、存储、网络、安全四项核心评比中均获高分,超过一些国际大厂。

展望未来,张献涛表示,在计算方面,一云多芯、异构计算是阿里云的长期战略,未来阿里云会引入和自研更多芯片,为客户提供性能更好、更具性价比的算力服务。另外,计算部门还将坚决贯彻阿里云的发展的策略,支持“一云多形态”,通过智能全托管、云盒、本地Region和中心Region等众多部署形态,让阿里云的服务更加靠近客户。同时,构建开放的生态,通过计算巢把阿里云的IaaS能力开放出来,让ISV和阿里云的客户能基于此更好地进行创新,更好地服务自己的客户,以加速各自的数字化转型进程。返回搜狐,查看更加多